Le POC fonctionne. Le modèle répond bien en démo. L’équipe est enthousiaste. Et maintenant ?
Mettre un LLM en production dans un contexte métier réel, c’est une opération d’une complexité catégoriquement différente du déploiement d’une API classique. Les équipes qui l’ont découvert après coup ont payé le prix fort : réponses hors-sujet en production, coûts d’inférence qui explosent, impossibilité d’auditer un comportement problématique, régression non détectée après un changement de prompt.
LLMOps désigne l’ensemble des pratiques qui permettent d’éviter ces écueils.
Ce qui rend les LLM différents des autres composants logiciels
Un composant logiciel classique est déterministe : les mêmes inputs produisent les mêmes outputs. Un LLM est probabiliste : les mêmes inputs produisent des outputs qui varient selon la température, le sampling, et l’état interne du modèle.
Cette propriété change fondamentalement la façon dont on teste, monitore et maintient le système.
Pas de test unitaire classique. On ne peut pas écrire assertEqual(llm.generate(prompt), expected_output). On écrit des évaluations probabilistes : sur 100 appels avec ce prompt, au moins 90% des réponses doivent satisfaire ces critères.
Pas de versioning classique. Quand le fournisseur met à jour son modèle de base (GPT-4 → GPT-4o, Claude 2 → Claude 3), le système change, même si rien n’a été touché côté applicatif. Et on peut ne pas le savoir.
Pas de debugging classique. Comprendre pourquoi le modèle a produit une réponse particulière n’est pas aussi simple que lire une stack trace.
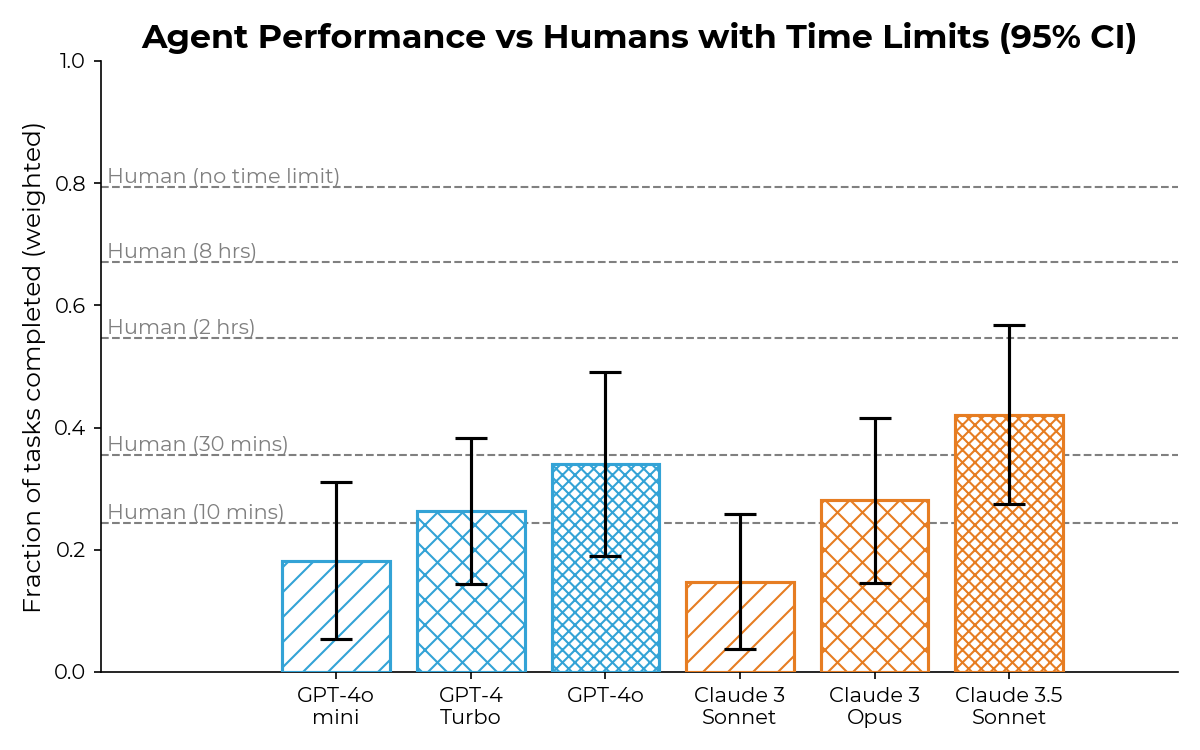
Source : METR, Evaluating Frontier AI (août 2024). Performance des agents IA sur des tâches nécessitant 30 min à 8h à un humain compétent. La progression entre 2019 et 2024 illustre pourquoi les pratiques LLMOps deviennent critiques : les modèles évoluent vite, et les systèmes qui les embarquent doivent suivre.
Les disciplines à instrumenter en continu
La gestion des prompts comme du code
Le prompt engineering est du développement. Les prompts doivent être versionnés, revus, testés et déployés avec les mêmes rigueurs que du code applicatif.
Concrètement :
- Les prompts sont stockés dans le dépôt de code (ou un système dédié comme LangSmith, PromptLayer)
- Chaque changement de prompt passe par une revue et une suite d’évaluations
- Le déploiement d’un nouveau prompt suit un pipeline CI/CD avec tests automatisés
- La version du prompt est loggée avec chaque appel en production
Un prompt modifié sans ces garde-fous peut dégrader silencieusement la qualité des réponses pendant des jours avant que quelqu’un s’en aperçoive.
L’évaluation systématique (evals)
Les evals sont l’équivalent LLM des tests automatisés. Ce sont des ensembles de cas de test avec des critères d’évaluation, exécutés avant chaque déploiement et régulièrement en production.
Trois familles coexistent. Les evals basées sur des critères objectifs : le modèle doit extraire une date d’un texte, la date est soit correcte, soit ne l’est pas, mesurable exactement. Les evals basées sur un modèle juge : un second LLM (souvent plus puissant) évalue la qualité de la réponse selon des critères définis (pertinence, exactitude, ton, longueur) ; plus flexible, mais introduit sa propre variance. Les evals humaines : un panel d’évaluateurs note les réponses selon une grille ; coûteux, lent, mais seul moyen d’évaluer des dimensions subjectives.
Ce qu’on cherche à mesurer :
- Taux de réponses dans le format attendu (JSON valide, longueur respectée)
- Taux de refus inappropriés (le modèle refuse de répondre alors qu’il le devrait)
- Taux d’hallucinations détectables (affirmations factuelles vérifiables)
- Cohérence entre appels (même question, réponse cohérente)
- Dérive par rapport à une baseline de référence
L’observabilité en production
Monitorer un LLM en production va bien au-delà de la latence et du taux d’erreur HTTP.
Métriques techniques :
- Latence time-to-first-token (TTFT) et latence totale
- Nombre de tokens consommés (entrée + sortie), directement corrélé au coût
- Taux d’erreur API (timeout, rate limiting, context length exceeded)
- Coût par appel, coût par session utilisateur, coût total
Métriques qualité :
- Distribution des scores d’évaluation automatique sur les appels en production
- Taux de feedback négatif utilisateur (si un mécanisme de feedback existe)
- Anomalies de longueur des réponses (réponses anormalement courtes ou longues)
- Détection de patterns de réponses hors-sujet
Les appels LLM s’insèrent dans des chaînes de traitements plus larges (RAG, agents, multi-step). Le tracing distribué (LangSmith, Arize Phoenix, ou OpenTelemetry avec des spans custom) permet de reconstituer le contexte complet d’un appel problématique.
La gestion du drift
Le drift en LLMOps a trois sources.
Drift du modèle. Le fournisseur met à jour le modèle sous-jacent. Même si le nom de l’endpoint reste identique (gpt-4), le comportement peut changer. La seule protection est de pin la version exacte du modèle (gpt-4-0613 plutôt que gpt-4) et d’avoir une suite d’evals qui détecte les régressions.
Drift des données. La distribution des inputs utilisateurs change avec le temps. Un modèle entraîné ou ajusté sur des données de janvier peut mal performer sur les patterns de juillet. La surveillance de la distribution des inputs (embedding drift) permet de détecter ces glissements.
Drift des prompts. L’accumulation de modifications de prompts peut créer des incohérences non détectées si chaque modification n’est pas testée dans le contexte global. La dérive cumulative est plus dangereuse que chaque modification prise isolément.
La maîtrise des coûts
Le coût d’un LLM en production est proportionnel au nombre de tokens traités. Un système mal conçu peut générer des coûts dix fois supérieurs aux estimations initiales.
Les leviers principaux :
Caching. Les réponses à des requêtes identiques ou très similaires peuvent être cachées. Les LLM providers proposent souvent un prompt caching (les tokens du système prompt ne sont pas refacturés à chaque appel).
Routing intelligent. Toutes les requêtes ne nécessitent pas le modèle le plus puissant. Un router qui dirige les requêtes simples vers un modèle moins coûteux (GPT-4o mini, Haiku) et les requêtes complexes vers le modèle premium peut diviser le coût par 5 à 10.
Optimisation des prompts. Les prompts verbeux coûtent plus cher. Un audit régulier des prompts pour supprimer les instructions redondantes réduit la consommation sans toucher à la qualité.
Batch processing. Pour les cas d’usage non temps réel (génération de rapports, enrichissement de données), le batch API est significativement moins cher (50% de réduction chez OpenAI).

Le pipeline de mise en production
Les disciplines décrites ci-dessus se cristallisent dans un pipeline que toute modification traverse : un nouveau prompt, un changement de version de modèle, une refonte de la chaîne RAG. Le pipeline n’est pas spécifique à LLMOps. Ce qui l’est, c’est ce qu’on contrôle à chaque étape.
Prompt et configuration. Point de départ : un changement versionné dans le dépôt, revu par les pairs, déposé comme n’importe quelle modification de code applicatif. Pas de modification de prompt direct en production, pas d’édition à chaud non tracée.
Evals automatisées. Le changement est exécuté contre un dataset de référence. Si le score reste sous le seuil défini, l’itération reprend : c’est la boucle de feedback la plus rapide du système, et la plus utile. Tant que les evals ne passent pas, rien ne descend dans le pipeline.
Shadow mode. Le nouveau prompt traite des requêtes réelles en parallèle de l’existant. Ses réponses ne sont pas servies aux utilisateurs, mais comparées au comportement actuel sur des cas en production. Ce mode détecte les régressions silencieuses que les evals automatiques ne couvrent pas : nouveaux types d’inputs, edge cases métier, interactions avec d’autres composants du système. C’est la dernière barrière avant l’exposition utilisateur.
Déploiement canary. Une fraction du trafic réel est routée vers le nouveau prompt : 5%, puis 25%, puis 100%. Chaque palier reste 24 à 48 heures sous monitoring avant de monter au suivant. Les métriques observées sont à la fois techniques (taux d’erreur API, latence, coût par appel) et qualité (taux de feedback négatif, dérive des scores d’eval en production). Une régression à un palier déclenche un rollback de configuration, qui doit être instantané.
Production et monitoring continu. Le nouveau prompt devient l’état de référence. La supervision continue alimente la prochaine itération : ce qui se passe en production produit les cas qui enrichiront le dataset d’evals, et les patterns observés deviennent les hypothèses du prochain changement.
Ce pipeline est une boucle, pas une ligne. Chaque mise en production renforce les capacités d’évaluation et de détection pour la suivante. Sans cette boucle, les disciplines décrites plus haut deviennent des bonnes intentions documentées.
Ce que l’AI Act change pour le LLMOps
Pour les systèmes IA à risque élevé (systèmes de prise de décision dans des domaines réglementés : finance, santé, emploi, justice), l’AI Act impose des exigences qui se traduisent directement en pratiques LLMOps :
- Journalisation : conservation des logs d’utilisation permettant une auditabilité a posteriori
- Supervision humaine : points de contrôle humain définis pour les décisions à fort impact
- Exactitude et robustesse : métriques d’évaluation documentées et maintenues
- Transparence : documentation des capacités et limitations du système
Ces exigences ne sont pas incompatibles avec une opération efficace, à condition de les intégrer dès la conception, pas en rattrapage.
Conclusion
Mettre un LLM en production sans pratiques LLMOps, c’est comme déployer une application sans monitoring ni tests. Ça peut fonctionner un temps, mais les problèmes arrivent au pire moment.
Les pratiques LLMOps ne sont pas des inventions. Elles s’appuient sur ce que le monde du DevOps a développé depuis vingt ans, adapté aux spécificités probabilistes des modèles de langage. Les équipes qui ont une culture MLOps solide ont déjà la moitié du chemin fait.
L’autre moitié, c’est comprendre ce qui est fondamentalement nouveau : l’évaluation probabiliste, la gestion du drift de modèle, et la traçabilité dans des systèmes agentiques multi-étapes.
Cadre général : IA contrôlée, notre doctrine d’ingénierie de systèmes IA en environnement réel.
Industrialiser un usage IA en contexte métier critique, instrumenter l’évaluation, la traçabilité et la dérive de modèle : c’est ce que nous faisons aux côtés des équipes techniques. Développement logiciel et maintien en condition de confiance.